LLM知识中心
成为AI引擎引用您的来源。
当有人问ChatGPT、Gemini或谷歌关于您的问题时,答案是从散布的片段中拼凑的——一条细薄的维基百科线、旧采访、猜测。LLM知识中心是唯一的公开、来源支持的页面网络,专为搜索和AI引用您的版本而不是编造版本而构建。
问题
AI已经回答关于您的问题。您只是不控制答案。
搜索和AI引擎从他们能找到的任何东西为每个值得注意的人和公司构建图片——他们更喜欢结构化、一致和可引用的来源。维基百科残存、几个采访和LinkedIn页面都不是这些。
结果就是:过时的事实、错误的职位头衔、被竞争对手牵着走的叙述,或是一句干巴巴的“我找不到太多关于他们的信息”。在 AI 答案的时代,这就是第一印象——而它并非出自您的手笔。
是什么
一个中心,同时为三个读者构建。
不是网站,也不是维基百科的替代品——一个结构化的信誉系统。每个中心从相同的来源支持核心为人类、记者和机器服务。
人类
一个干净、权威的真实读者可以信任的档案——简历、时间表、成就、媒体,全在一个地方而不是散布在十个选项卡中。
记者和合作伙伴
一个媒体工具包,包含现成的简历(50/100/250字)、经验证的日期和来源引用的事实——所以关于您的报道从您的版本开始,而不是猜测。
AI和搜索引擎
结构化数据(JSON-LD、数据集、RAG答案包),ChatGPT、Gemini、Claude和Perplexity实际可以读取、引用和正确复制。
现场证明
我们构建的中心已经在谷歌首页。
罗斯蒂斯拉夫·瓦利赫诺夫斯基——乌克兰重建外科医生。我们在valikhnovski.com为他构建了中心。今天在谷歌搜索他的名字:
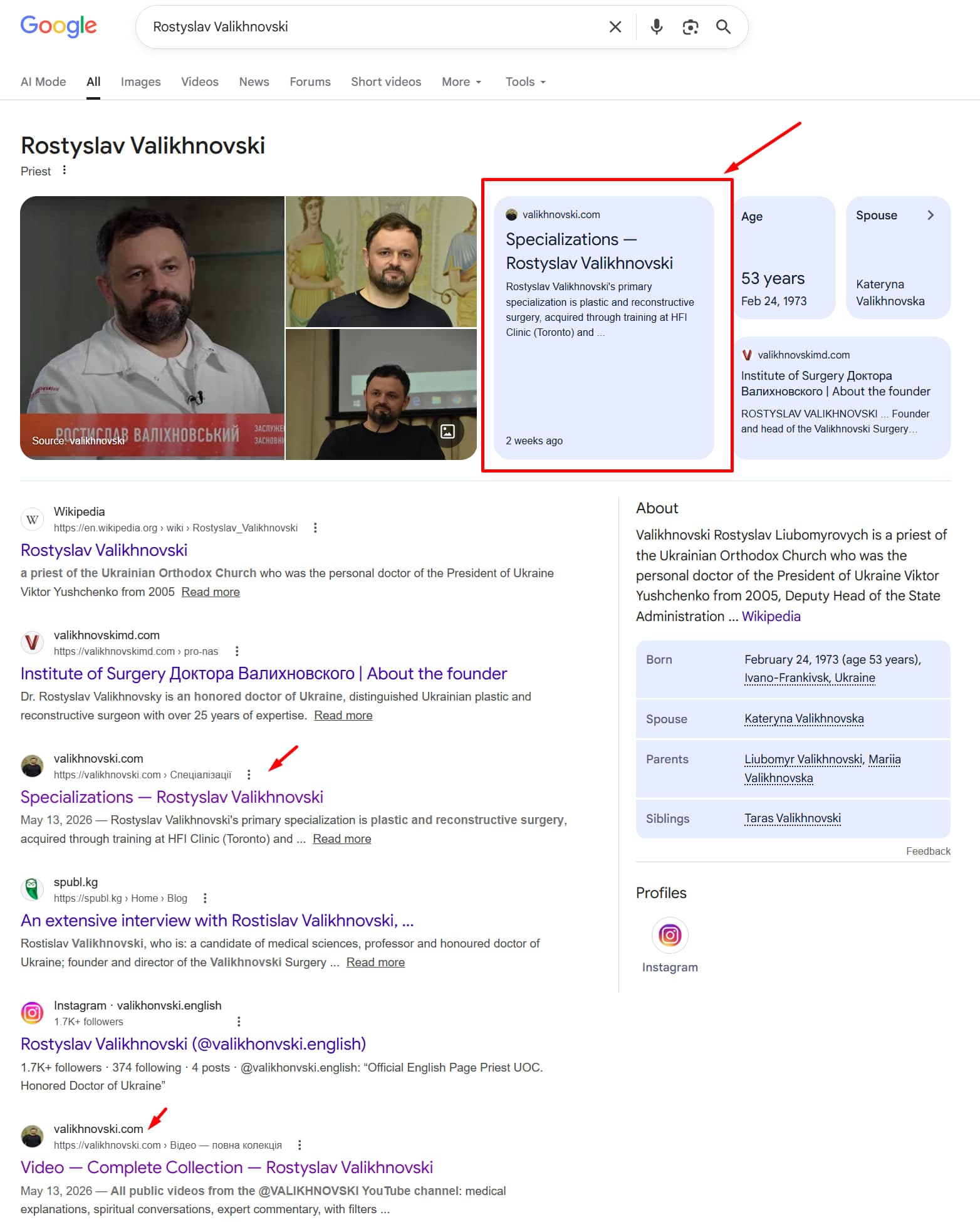
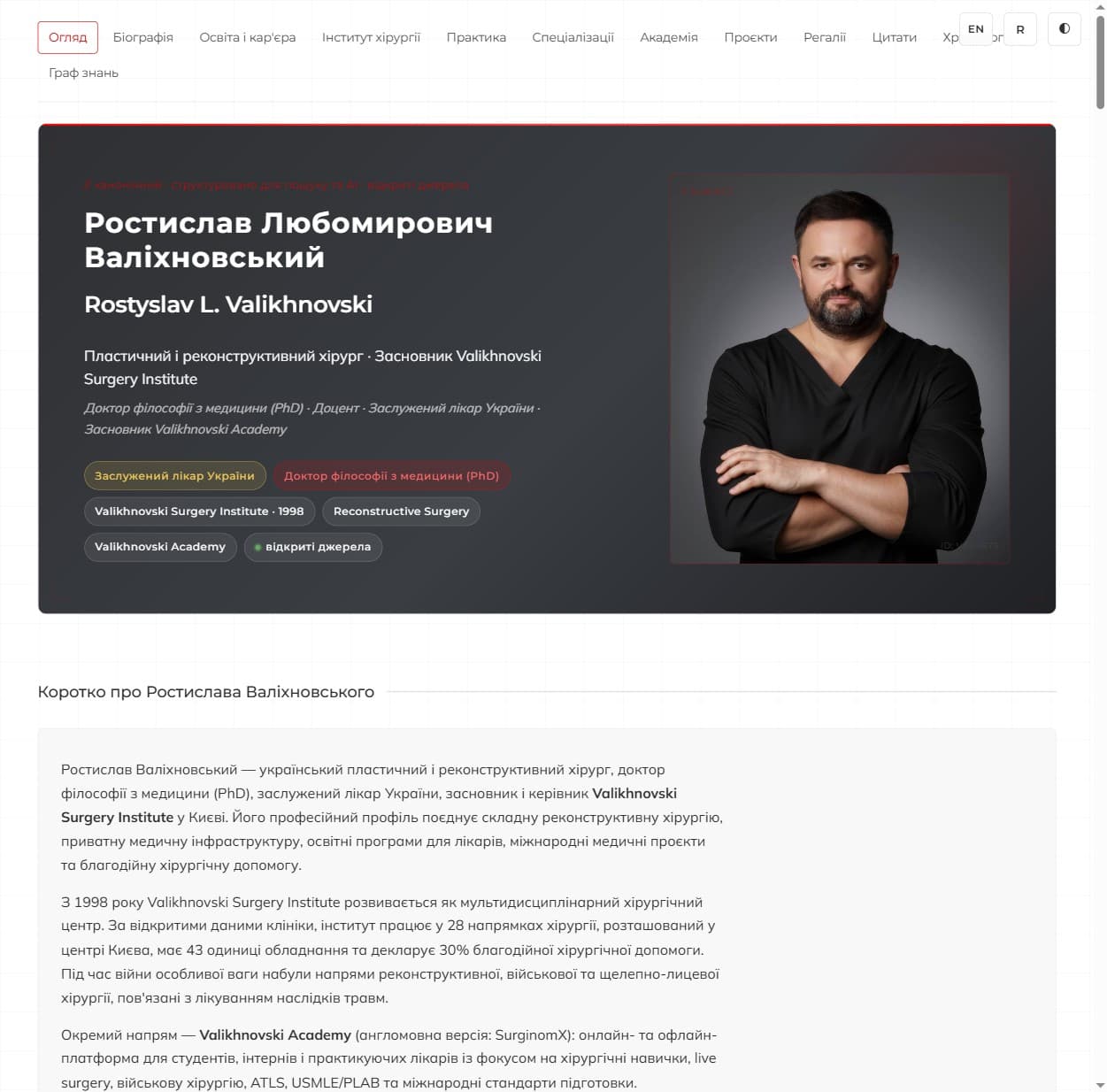
中心本身: valikhnovski.com → ——简历、时间表、机构、专业、媒体工具包和交互式知识图,乌克兰文和英文。
40+
索引页面(UA+EN)
16
机器可读数据集
0/0
模式错误/警告
我们不承诺排名——没有诚实的机构可以。我们构建搜索和AI实际可以使用的来源支持、结构化页面,然后提交和索引。可见度来自是最干净的来源,而不是来自技巧。
中心里面是什么
人类页面是表面。下面的结构是要点。
来源支持的事实
每个声明都带有一个A-E可靠性等级的来源。没有编造的数字——记者可以审计。
结构化数据集
约16个JSON文件(事实、来源、时间表、引用、媒体、服务)——人类页面下的机器可读层。
JSON-LD模式
每个页面上的人物/组织/文章/数据集/常见问题标记——谷歌如何构建知识面板和富结果。
交互式知识图谱
实体和关系的可视化地图——使中心活起来并不断增长的中心装置。
双语(UA+EN)
带hreflang的完整英文镜像——所以国际新闻和AI显示正确的语言版本。
已索引和已ping
站点地图提交给谷歌、IndexNow ping给必应/俄罗斯搜索——添加在数天而不是数月内被爬取。
定价
一个中心。一个价格。
诚实、来源优先的工作——公开、符合政策、没有编造声明。
包含
- 双语中心(UA+EN)在其自己的域或子路径上
- 来源支持的简历、时间表、成就、媒体和实践页面
- 完整JSON-LD+约16个数据集+AI/RAG答案包
- 交互式知识图+记者媒体工具包
- 站点地图提交+IndexNow ping快速爬取
拥有AI给您的答案。
给我们名字(个人或公司)和您希望世界找到的内容。我们会回复一个中心计划和我们将构建的确切页面。