Hub de connaissances LLM
Devenez la source que les moteurs IA citent sur vous.
Quand quelqu'un demande à ChatGPT, Gemini ou Google sur vous, la réponse est cousue à partir de fragments dispersés — une ligne Wikipédia mince, de vieilles interviews, des suppositions. Un Hub de connaissances LLM est le seul réseau public et appuyé par des sources construit afin que la recherche et l'IA citent votre version au lieu d'en inventer une.
Le problème
L'IA répond déjà à des questions sur vous. Vous ne contrôlez juste pas la réponse.
Les moteurs de recherche et d'IA construisent une image de chaque personne et entreprise notable à partir de ce qu'ils peuvent trouver — et ils préfèrent les sources qui sont structurées, cohérentes et citable. Une ébauche Wikipédia, quelques interviews et une page LinkedIn ne sont aucune de ces choses.
Le résultat : des faits périmés, le mauvais titre de travail, l'encadrement d'un concurrent, ou un plat « Je n'ai pas trouvé grand-chose à leur sujet. » À l'époque de la réponse IA, c'est la première impression — et vous ne l'avez pas écrite.
Ce que c'est
Un hub, construit pour trois lecteurs à la fois.
Pas un site web et pas une alternative à Wikipédia — un système de réputation structuré. Chaque hub sert les humains, les journalistes et les machines du même cœur appuyé par des sources.
Personnes
Un profil clair et fiable qu’un vrai lecteur peut consulter avec confiance — bio, chronologie, accomplissements, médias, tout au même endroit plutôt que dispersé sur dix onglets.
Journalistes & partenaires
Un kit médias avec des bios prêts à copier (50 / 100 / 250 mots), des dates vérifiées et des faits sourcés — afin que la couverture sur vous commence par votre version, pas une supposition.
IA & moteurs de recherche
Données structurées (JSON-LD, ensembles de données, un paquet de réponses pour RAG) que ChatGPT, Gemini, Claude et Perplexity peuvent réellement lire, citer et reproduire correctement.
Preuve en direct
Un hub que nous avons construit est déjà à la première page de Google.
Rostyslav Valikhnovski — un chirurgien reconstructeur ukrainien. Nous avons construit son hub sur valikhnovski.com. Cherchez son nom sur Google aujourd'hui :
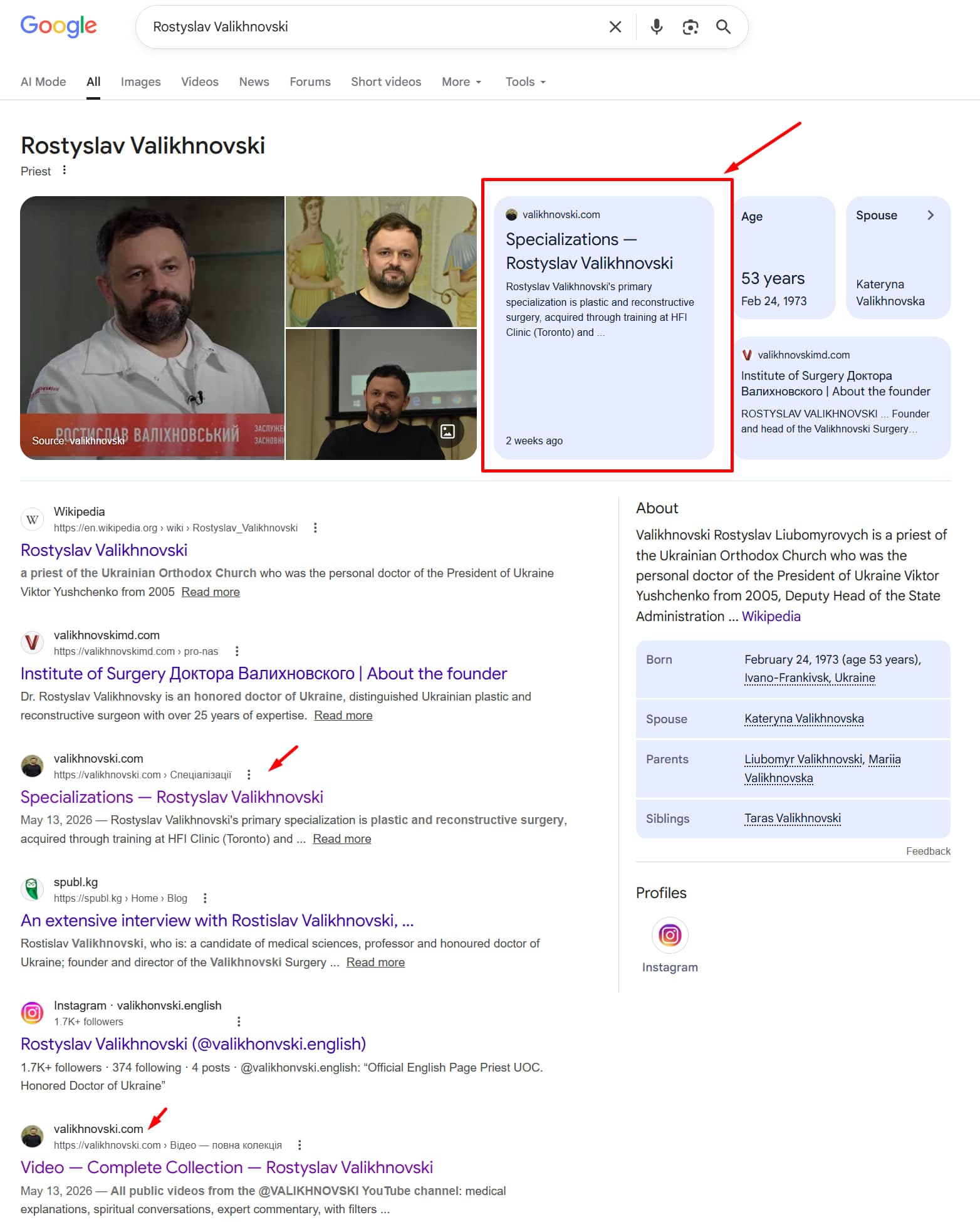
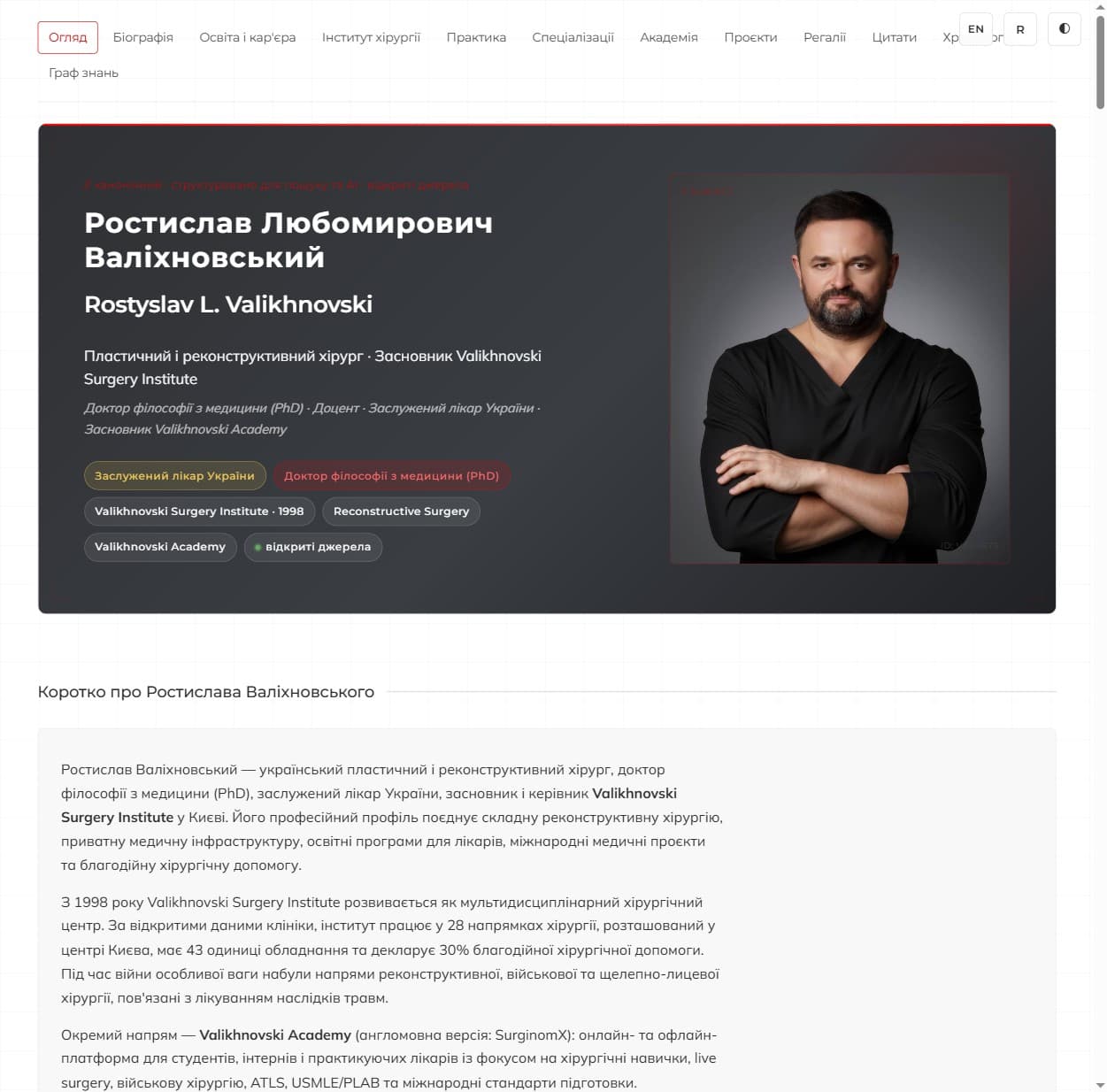
Le hub lui-même : valikhnovski.com → — bio, chronologie, institut, spécialisations, kit médias et un graphique de connaissances interactif, en ukrainien et anglais.
40+
pages indexées (UA + EN)
16
ensembles de données lisibles par machine
0/0
erreurs de schéma / avertissements
Nous ne promettons pas un classement — aucune agence honnête ne peut. Nous construisons la page appuyée par des sources et structurée que la recherche et l'IA peuvent réellement utiliser, puis la soumettons et l'indexons. La visibilité suit le fait d'être la source la plus propre, pas un truc.
Ce qui se trouve à l'intérieur d'un hub
La page humaine est la surface. La structure dessous est le point.
Faits appuyés par des sources
Chaque affirmation porte une source avec une note de fiabilité A–E. Pas de chiffres inventés — vérifiable par un journaliste.
Ensembles de données structurés
~16 fichiers JSON (faits, sources, chronologie, citations, médias, services) — la couche lisible par machine sous les pages humaines.
Schéma JSON-LD
Marquage Personne / Organisation / Article / Ensemble de données / FAQ sur chaque page — comment Google construit le panneau de connaissances et les résultats enrichis.
Graphique de connaissances interactif
Une carte visuelle d'entités et de relations — la pièce maîtresse qui rend le hub vivant et continue de croître.
Bilingue (UA + EN)
Un miroir anglais complet avec hreflang — afin que la presse internationale et les moteurs IA servent la bonne version linguistique.
Indexé & pinché
Plan du site soumis à Google, ping IndexNow à Bing/Yandex — les ajouts sont explorés dans les jours, pas les mois.
Tarification
Un hub. Un prix.
Travail honnête, axé sur la source — divulgué, conforme à la politique, pas de réclamations manufacturées.
Hub de connaissances LLM
€1 000
Délai de mise en œuvre : 2–3 semaines.
Commande un hub →L'actualisation mensuelle optionnelle garde les faits et le graphique à jour.
Inclus
- Un hub bilingue (UA + EN) sur son propre domaine ou sous-chemin
- Bio appuyée par des sources, chronologie, accomplissements, pages médias et pratique
- JSON-LD complet + ~16 ensembles de données + paquet de réponses pour l'IA/RAG
- Graphique de connaissances interactif + kit médias journaliste
- Soumettre un plan du site + ping IndexNow afin qu'il soit exploré rapidement
Où aller ensuite
Pages que les visiteurs ouvrent après celle-ci
llms.txt en 2026 — les données
Ce que 515 M d'événements de bots révèlent sur les fichiers de crawl IA.
Notre couche lisible par machine
L'exemple en direct : entités, politique TDM, licence ouverte.
Wikipedia AEO
Combinez le hub propriétaire avec la couche publique de haute confiance.
Hub de visibilité IA
La place du LLM Hub dans la pile de visibilité complète.
Possédez la réponse que l'IA donne sur vous.
Envoyez-nous le nom (une personne ou une entreprise) et ce que vous aimeriez que le monde trouve. Nous reviendrons avec un plan de hub et les pages exactes que nous construirions.