Pourquoi ça compte · L'ère de l'IA
L'IA répond à vos clients avant Google. Wikipédia est ce qu'elle lit.
800 millions de personnes interrogent ChatGPT chaque semaine, et 2 milliards voient les réponses IA de Google chaque mois — et ces modèles ne lisent pas votre site. Ils lisent Wikipédia, Wikidata et Reddit. Nous construisons et défendons les sources vérifiées qui déterminent ce que l'IA dit de vous.
15 ans · 4 000+ projets Wikipédia & Wikidata · 93 % survivent à la révision de Wikipédia · 160+ langues
L'audit gratuit montre ce que ChatGPT, Claude, Gemini & Perplexity disent de vous aujourd'hui — et un plan pour combler les lacunes. Sans engagement, sans argumentaire de vente.
Soyez la source que chaque moteur cite
- 3,4×
- Nombre de fois que GPT-3 a été entraîné sur Wikipédia — contre 0,44× pour l'ensemble du web ouvert.
- N°1
- Source la plus citée dans les réponses ChatGPT : Wikipédia.
- 1 %
- Des utilisateurs cliquent sur un lien dans une réponse IA de Google. La réponse est maintenant la destination.
- ~60M$
- Ce que Google paierait à Reddit chaque année pour entraîner l'IA sur ses conversations.
Article GPT-3, OpenAI 2020
Ahrefs, 78,6M requêtes, 2025
Pew Research, 2025
CBS News / Reuters, 2024
Preuve, pas théorie
Ce que les acheteurs et les systèmes d'IA voient réellement
Wikipedia n'est pas qu'une simple page. Elle devient la couche source derrière les cartes d'entités de recherche, les résumés d'IA et les vérifications de due diligence. Voici une personnalité publique sur trois surfaces réelles et publiques — chacune lisant le même enregistrement Wikipedia et Wikidata.
 Source : Wikipedia
Source : Wikipedia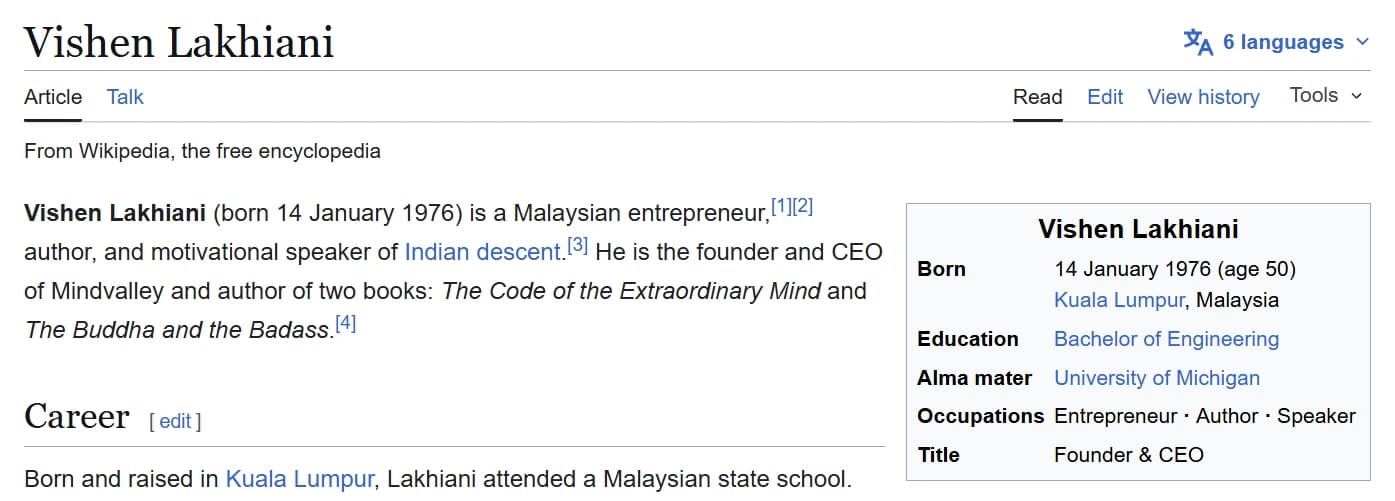
 Lisible par machine
Lisible par machineLes captures d'écran sont des exemples publics à titre d'illustration. Les interfaces de recherche et d'IA changent fréquemment ; les résultats ne sont pas garantis.
Travaux sélectionnés
Pages que nous avons construites — et défendues
15 ans. 4 000+ entreprises, fondateurs et agences. 160+ éditions linguistiques Wikipédia. Quelques entrées que vous pouvez vérifier maintenant :
Fait confiance par des fondateurs & PDG, des directeurs marketing et des équipes de communication, et des agences RP / SEO (en marque blanche).
- 15 ans
- Construction et défense de la présence Wikipédia depuis 2010.
- 4 000+
- Entreprises, fondateurs et agences servis.
- 93 %
- De nos pages survivent à la révision de suppression de Wikipédia.
- 1 000+
- Pages créées et modifiées chaque année.
Le basculement
La recherche n'est pas morte. Elle s'est déplacée à l'intérieur de la réponse.
Pendant 20 ans, l'enjeu était de se classer en première page Google et d'obtenir le clic. L'IA générative a changé la destination : les gens lisent désormais la réponse et s'arrêtent. Se classer n°1 importe moins qu'être la source sur laquelle la réponse est construite.
15% → 8%
Clics vers un site quelconque lorsqu'un résumé IA de Google apparaît
Pew Research, 2025
1%
Des utilisateurs cliquent sur un lien à l'intérieur de la réponse IA elle-même
Pew Research, 2025
~60%
Des recherches Google se terminent désormais sans aucun clic
Bain & Company, 2025
Gartner prédit une baisse de 25 % du volume de recherche traditionnel d'ici 2026, les utilisateurs se tournant vers les assistants IA. Que le chiffre exact se confirme ou non, la direction est indéniable — et elle récompense les marques qui possèdent les sources auxquelles l'IA fait confiance, pas seulement les mots-clés que Google classe.
Comment ça fonctionne
Comment l'IA décide ce qu'elle dit de vous
Une réponse IA sur votre entreprise n'est pas extraite de votre site web. Elle est assemblée à partir des sources auxquelles le modèle fait confiance. Voici le chemin que votre marque doit parcourir pour atterrir dans cette réponse — avec exactitude.
Votre marque
- Entreprise / fondateur
Sources auxquelles l'IA se fie
- Wikipedia
- Wikidata
- Reddit · Quora
- Médias de premier plan
Moteurs de réponse IA
- ChatGPT · Claude
- Gemini · Perplexity
- AI Overviews
Ce que voit votre acheteur
- Une réponse
- précise et sourcée
- à votre sujet
Absent des sources ? Le modèle n'a rien de fiable à lire — alors il paraphrase, utilise des faits périmés, hallucine ou cite un concurrent à la place.
Trois couches, une vérité
L'IA vous lit dans trois endroits — Wikipédia est présent dans tous
La couche d'entraînement
Chaque modèle dont la recette d'entraînement est publiée sur-échantillonne Wikipédia. GPT-3 lui a accordé 3 % du mélange mais l'a montré 3,4× — plus que toute autre source — tout en montrant l'ensemble du web ouvert moins d'une fois. Meta LLaMA : 4,5 %. Les modèles de pointe gardent leurs recettes secrètes, mais le schéma est constant.
La couche de récupération
Quand ChatGPT, Perplexity, Gemini ou les AI Overviews de Google cherchent quelque chose en direct, ils se tournent d'abord vers le même ensemble à haute confiance : Wikipédia, Wikidata, Reddit, Quora et les médias de premier rang. Ce sont les domaines que l'IA cite le plus.
La couche d'entité
Derrière chaque réponse confiante se trouve une entité — généralement un Q-ID Wikidata. Avec un Q-ID, l'IA vous traite comme une entreprise connue avec des faits vérifiés. Sans lui, vous êtes une chaîne de lettres sur laquelle elle doit deviner.
Ce qui est en jeu
En ce moment même, l'IA répond à des questions sur vous. Les réponses sont-elles exactes ?
La différence entre une réponse confiante et citée et un haussement d'épaules — ou pire, le nom d'un concurrent — tient à ce que l'IA dispose de sources fiables pour vous.
« Je n'ai pas d'informations fiables sur Acme Robotics. Il s'agit peut-être d'une entreprise plus petite — vous voudrez sans doute consulter directement leur site officiel. »
« Acme Robotics est une entreprise de robotique d'entrepôt autonome fondée en 2018, dont le siège est à Austin, au Texas. Elle a levé une Série B en 2024 et est dirigée par son PDG Jordan Lee. »
Les preuves
Wikipédia est la source à laquelle l'IA fait le plus confiance — par conception
Ce n'est pas une affirmation marketing. Cela apparaît dans les propres recettes d'entraînement des modèles et dans chaque grande étude sur ce que l'IA cite.
Données d'entraînement
Wikipédia est la source la plus sur-échantillonnée dans GPT-3
Citations en direct
Domaines les plus cités dans ChatGPT (illustration)
Couverture
Chaque moteur lit un mélange différent. Nous les couvrons tous.
Aucune source unique ne domine tous les moteurs IA — Wikipédia mène sur ChatGPT, Reddit mène sur Perplexity et les AI Overviews, Wikidata alimente le Knowledge Graph. Une présence coordonnée vous rend visible partout où vos acheteurs posent des questions.
| Source lue par l'IA | ChatGPT | Perplexity | Gemini | AI Overviews | WikiBusines |
|---|---|---|---|---|---|
| Wikipedia | |||||
| Quora | |||||
| Wikidata / Knowledge Graph | |||||
| Médias de premier plan |
Wikidata · Knowledge Graph
Wikidata, c'est vous en version lisible par les machines
Wikipédia est l'histoire ; Wikidata en sont les faits structurés. Ensemble avec Wikimedia Commons, ils alimentent le Knowledge Graph de Google — le moteur derrière le Knowledge Panel, les assistants vocaux et les faits que les LLM retournent à votre sujet.
Le pipeline
Google Knowledge Graph
Plus de 8 Md de faits sur des personnes, lieux et entreprises
Une entité Wikidata propre — avec les bons identifiants, dates et relations — élève le plancher de précision avec lequel l'IA vous décrit. Souvent, elle fait évoluer les choses plus que l'article Wikipédia lui-même. Voir comment fonctionne le travail Wikidata →
Ce que ça construit sur Google
Acme Robotics
Entreprise technologique
Acme Robotics est une entreprise de robotique qui conçoit des systèmes d'entrepôt autonomes. Elle a été fondée en 2018 et son siège est à Austin, au Texas. depuis Wikipedia
- Fondée
- 2018 · Austin, TX Wikidata
- PDG
- Jordan Lee Wikidata
- Secteur
- Robotique industrielle
Nous ne garantissons pas un Knowledge Panel — les systèmes de Google prennent cette décision. Notre travail consiste à construire la fondation d'entité vérifiée qui augmente matériellement la probabilité, puis à la suivre.
Reddit · Quora
Là où l'IA va chercher l'opinion « vraie »
Les encyclopédies donnent à l'IA les faits ; les communautés lui donnent le verdict. Reddit et Quora font maintenant partie des sources les plus citées dans les réponses IA — et Google paie pour ce privilège.
~60M$/an
Valeur rapportée de l'accord de Google pour licencier le contenu Reddit pour l'entraînement et la recherche.
CBS News / Reuters, 2024
85e → 7e
L'ascension de Reddit parmi les domaines les plus visibles dans la recherche Google en moins d'un an.
Sistrix via Amsive, 2024
N°1
Domaine le plus cité dans les AI Overviews de Google et Perplexity : Reddit.
Profound, 680M citations, 2025
Quand les gens veulent un avis honnête, ils ajoutent “reddit” à leur recherche. L'IA fait de même. Une présence conforme et non promotionnelle dans les bonnes communautés fait désormais partie de la façon dont une marque reste représentée avec précision dans les réponses IA. Explorer la visibilité IA Reddit →
Autorité & portée mondiale
Le domaine le plus autoritaire du web ouvert
Wikipédia enregistre en moyenne 508 millions de vues par jour sur 66 millions d'articles et 342 langues. Son autorité explique pourquoi Google et l'IA s'y appuient — et pourquoi une page dans chaque marché renforce votre crédibilité à l'échelle mondiale.
Autorité de domaine par édition Wikipédia
| Langue | Domaine | Domain Rating | Trafic est. |
|---|---|---|---|
| English | en.wikipedia.org | 96 | ~4.4B / mo |
| German | de.wikipedia.org | 93 | ~320M / mo |
| French | fr.wikipedia.org | 93 | ~280M / mo |
| Spanish | es.wikipedia.org | 92 | ~500M / mo |
| Portuguese | pt.wikipedia.org | 91 | ~165M / mo |
| Chinese | zh.wikipedia.org | 90 | ~140M / mo |
| Arabic | ar.wikipedia.org | 90 | ~95M / mo |
| Ukrainian | uk.wikipedia.org | 85 | ~40M / mo |
- DR 96
- Domain Rating Ahrefs de en.wikipedia.org
- 508M
- Vues Wikipédia moyennes par jour
- 160+
- Éditions linguistiques dans lesquelles nous publions et maintenons
Ahrefs, 2026
Pew Research, 2026
WikiBusines
L'argument économique
Ce qu'une présence Wikipédia bien construite vous apporte
Un seul actif, qui travaille pour vous dans la recherche, les réponses IA, la presse et la salle du conseil.
Devenez la source que l'IA cite
Soyez la référence vérifiée que ChatGPT, Claude, Gemini et Perplexity lisent — plutôt que d'être paraphrasé, obsolète ou écarté au profit d'un concurrent.
Déclenchez le Knowledge Panel Google
Wikipédia + Wikidata sont les signaux les plus forts pour la carte en colonne de droite qui cadre votre marque dès que quelqu'un cherche votre nom.
Occupez la première page pour votre nom de marque
Wikipédia affiche un Domain Rating Ahrefs de 96 et se classe pour ~45M de mots-clés. Une page verrouille une visibilité durable et à forte intention — sans dépense publicitaire.
Réussir la due diligence
Les journalistes, analystes, partenaires et investisseurs consultent d'abord Wikipédia. Une page neutre et bien sourcée est souvent le moment décisif « cette entreprise est réelle » dans les contrôles B2B et médias.
Atteindre chaque marché
Plus de 160 éditions linguistiques signifient une crédibilité immédiate et localisée dans les régions où vous vendez — chacune une source de confiance lisible par l'IA.
Un actif qui se capitalise
Construite une fois et maintenue, une empreinte Wikipédia/Wikidata continue de générer confiance et visibilité pendant des années — sur des surfaces de recherche qui n'existaient pas quand vous avez commencé.
L'écosystème de visibilité IA
Huit plateformes façonnent ce que l'IA dit de votre marque
Les moteurs de réponse IA lisent les mêmes sources de haute autorité auxquelles les humains font confiance. La couverture sur chaque plateforme se cumule — les lacunes sur l'une d'elles sont perceptibles.
Encyclopédie
Wikipedia
Plus de 160 éditions linguistiques — la référence la plus citée du web ouvert.
Pourquoi : Fortement pondérée par tous les grands LLM. La plus grande source de contexte de marque pour les réponses IA.
Données structurées
Wikidata
Knowledge graph ouvert — entités, relations et identifiants sous forme lisible par machine.
Pourquoi : Alimente le Knowledge Graph de Google et est lu directement par les pipelines de récupération des LLM.
Communauté
Fils de discussion répartis sur des milliers de communautés.
Pourquoi : Les systèmes d'IA citent les fils Reddit comme « avis réel d'utilisateurs ». Souvent affichés dans les résultats Google.
Q&R / réponses IA
Quora
Plateforme de questions-réponses avec des réponses d'experts détaillées.
Pourquoi : Fort référencement organique et citation directe par les moteurs de réponse IA.
Données structurées
Google Knowledge Panel
La fiche affichée à droite des résultats de recherche Google.
Pourquoi : Première impression pour environ 80 % des recherches de marque. Alimentée par Wikipedia + Wikidata.
Q&R / réponses IA
ChatGPT / Gemini / Perplexity
Moteurs de réponse à IA générative.
Pourquoi : Là où les acheteurs se renseignent de plus en plus sur les marques avant de passer à Google.
Médias
Médias de niveau 1 et 2
Médias indépendants qui répondent au critère de source fiable de Wikipedia.
Pourquoi : La colonne vertébrale de l'admissibilité. Sans eux, aucune page Wikipedia n'est à l'abri de la suppression.
Wiki alternatif
Simple English Wikipedia
Des standards éditoriaux simplifiés sur la même infrastructure Wikipedia.
Pourquoi : Une voie de publication plus facile qui hérite tout de même de l'autorité de domaine de Wikipedia.
Le défi
Pourquoi vous ne pouvez pas simplement la rédiger vous-même
Wikipédia est une communauté indépendante avec des règles strictes, publiques et impitoyables. C'est exactement ce qui rend une page précieuse — et exactement pourquoi c'est risqué de le faire soi-même.
200+ règles et politiques
Notoriété, sources fiables, point de vue neutre, conflits d'intérêts — Wikipédia est une encyclopédie, pas un canal marketing. Le ton promotionnel est signalé ou supprimé.
La plupart des pages auto-rédigées sont rejetées
Les estimations du secteur situent le taux de rejet des pages rédigées par les entreprises elles-mêmes entre 80 et 90 % — sourcing tiers insuffisant, ton promotionnel ou absence de notoriété.
Vous ne pouvez pas rédiger la vôtre
Écrire sur soi-même est un conflit d'intérêts. S'il est découvert que des employés ont rédigé la page, elle peut être balisée ou supprimée — et la confiance des éditeurs est difficile à reconstruire.
Une mauvaise tentative peut vous blacklister
Des tentatives de suppression répétées laissent un historique permanent et peuvent bloquer toute création future. La route du freelance à 50 $ bon marché, c'est ainsi que les marques se font exclure.
La comparaison honnête
Soi-même vs freelance vs nous
| En interne soi-même | Freelance Upwork | Agence non spécialisée | WikiBusines | |
|---|---|---|---|---|
| Notabilité évaluée avant de payer | Parfois | |||
| Rédaction encyclopédique, sans conflit d'intérêts | Risqué | Risqué | ||
| Entité Wikidata / Knowledge Graph | ||||
| Visibilité IA sur Reddit et Quora | Rarement | |||
| Suivi et défense après publication | Parfois | |||
| Remboursement si une page supprimée n'est pas restaurée | ||||
| Survit à un examen de suppression | ~10–15% | Faible | Variable | 93% de réussite |
Un cadre honnête
Ce que nous promettons — et ce que nous ne promettons pas
Le marché des services Wikipédia est plein de garanties impossibles à tenir. Voici la ligne que nous maintenons.
Nous le ferons
Vous dire quand la base de sources justifie une page Wikipédia — et quand ce n'est pas le cas.
Nous le ferons
Construire une présence fiable, neutre et vérifiée par les sources sur Wikipedia, Wikidata, Reddit et Quora.
Nous le ferons
Rembourser 80% des honoraires du projet si une page supprimée ne peut pas être restaurée après 3 tentatives dans la fenêtre de 90 jours.
Nous ne le ferons pas
Garantir la publication sur Wikipédia. Wikipédia est une communauté indépendante avec son propre processus de révision éditorial.
Nous ne le ferons pas
Promettre un Google Knowledge Panel. Les systèmes de Google prennent cette décision — nous augmentons matériellement la probabilité.
Nous ne le ferons pas
Prétendre injecter du contenu dans ChatGPT ou tout autre modèle. Nous construisons l'infrastructure de sources que les systèmes IA lisent.
Questions fréquentes
Tout ce que vous devez savoir avant de commander
Éligibilité à Wikipedia
Comment déterminez-vous si une entreprise est éligible à Wikipedia ?
Quels sujets refusez-vous ?
Qu'est-ce qu'une source fiable ?
Les communiqués de presse comptent-ils comme sources ?
Notre couverture est principalement dans la presse spécialisée — est-ce suffisant ?
Processus et délais
Combien de temps prend la création d'une page Wikipedia ?
Que se passe-t-il après la publication de la page ?
Comment les modifications sont-elles effectuées sur les pages existantes ?
Vous ne traduisez pas — vous « localisez ». Qu'est-ce que cela signifie ?
Garanties et politique de risque
Garantissez-vous la publication d'une page ?
Que se passe-t-il si une page est supprimée après la publication ?
Pouvez-vous garantir un Google Knowledge Panel ?
Déclarez-vous que vous êtes rémunéré pour modifier Wikipedia ?
Visibilité IA
Pourquoi Wikipedia compte-t-il pour ChatGPT et la recherche IA ?
En quoi la visibilité IA diffère-t-elle du SEO ?
Pouvez-vous garantir que votre marque apparaîtra dans les réponses de ChatGPT ?
Peut-on obtenir un Google Knowledge Panel sans page Wikipedia ?
Sources & méthodologie
Chaque chiffre sur cette page est sourcé
Nous construisons des pages — y compris celle-ci — de la façon dont l'IA récompense : avec des statistiques vérifiables, des citations et des sources référencées. Les parts de citation varient selon le moteur, l'étude et le mois, nous les présentons donc comme des fourchettes et pointons vers les recherches.
- OpenAI / Brown et al. — Language Models are Few-Shot Learners (GPT-3), Table 2.2 (May 2020)
- Meta AI / Touvron et al. — LLaMA: Open and Efficient Foundation Language Models, Table 1 (Feb 2023)
- Ahrefs Brand Radar — Top 10 Most Cited Domains by AI Assistants (78.6M queries) (Jun 2025)
- Profound — AI Platform Citation Patterns (680M citations) (Jun 2025)
- Similarweb — Most-cited domains in ChatGPT answers (~600K citations) (Jan–Feb 2026)
- Pew Research Center — Google users are less likely to click when an AI summary appears (Jul 2025)
- Pew Research Center — Wikipedia at 25: what the data tells us (Jan 2026)
- Wikimedia Foundation — New user trends on Wikipedia (Oct 2025)
- Bain & Company — Consumer reliance on AI search results (Feb 2025)
- Aggarwal et al., Princeton / KDD 2024 — GEO: Generative Engine Optimization (GEO-bench, 10,000 queries) (Nov 2023)
- CBS News / Reuters — Google to pay Reddit ~$60M/year to train AI on its content (Feb 2024)
- Amsive — Reddit's explosive SEO growth (Sistrix / Ahrefs data) (May 2024)
- OpenAI (Sam Altman) via TechCrunch — ChatGPT has hit 800M weekly active users (Oct 2025)
- Alphabet Q2'25 (Sundar Pichai) via TechCrunch — Google's AI Overviews have 2B monthly users (Jul 2025)
- Gartner — Gartner predicts search engine volume will drop 25% by 2026 (Feb 2024)
- Ahrefs — Wikipedia Domain Rating & keyword footprint (Mar 2026)
Vous voulez voir ce que l'IA dit de vous en ce moment ?
Nous effectuerons un audit de visibilité IA gratuit — ce que ChatGPT, Claude, Gemini et Perplexity disent de votre marque aujourd'hui, où se trouvent les lacunes de sources, et un plan réaliste pour les combler. Sans engagement, sans argumentaire de vente.