Perché è importante · L'era dell'AI
L'AI risponde ai Suoi clienti prima di Google. Wikipedia è ciò che legge.
800 milioni di persone chiedono a ChatGPT ogni settimana, e 2 miliardi vedono le risposte AI di Google ogni mese — e quei modelli non leggono il Suo sito web. Leggono Wikipedia, Wikidata e Reddit. Costruiamo e difendiamo le fonti verificate che decidono cosa dice l'AI di Lei.
15 anni · Oltre 4.000 progetti Wikipedia & Wikidata · 93% supera la revisione di Wikipedia · Oltre 160 lingue
L'audit gratuito mostra cosa dicono oggi ChatGPT, Claude, Gemini & Perplexity di Lei — e un piano per colmare le lacune. Nessun obbligo, nessuna presentazione commerciale.
Sia la fonte citata da ogni motore
- 3,4×
- Quante volte GPT-3 è stato addestrato su Wikipedia — vs 0,44× per l'intero web aperto.
- #1
- Fonte più citata nelle risposte ChatGPT: Wikipedia.
- 1%
- Degli utenti clicca un link all'interno di una risposta AI di Google. La risposta è ora la destinazione.
- ~$60M
- Quanto Google paga apparentemente Reddit ogni anno per addestrare l'AI sulle sue conversazioni.
Paper GPT-3, OpenAI 2020
Ahrefs, 78,6M query, 2025
Pew Research, 2025
CBS News / Reuters, 2024
Prova, non teoria
Cosa vedono davvero acquirenti e sistemi di IA
Wikipedia non è solo una pagina. Diventa il livello sorgente dietro le schede entità di ricerca, i riepiloghi IA e le verifiche di due diligence. Ecco una figura pubblica su tre superfici reali e pubbliche — ognuna legge dallo stesso record Wikipedia e Wikidata.
 Fonte: Wikipedia
Fonte: Wikipedia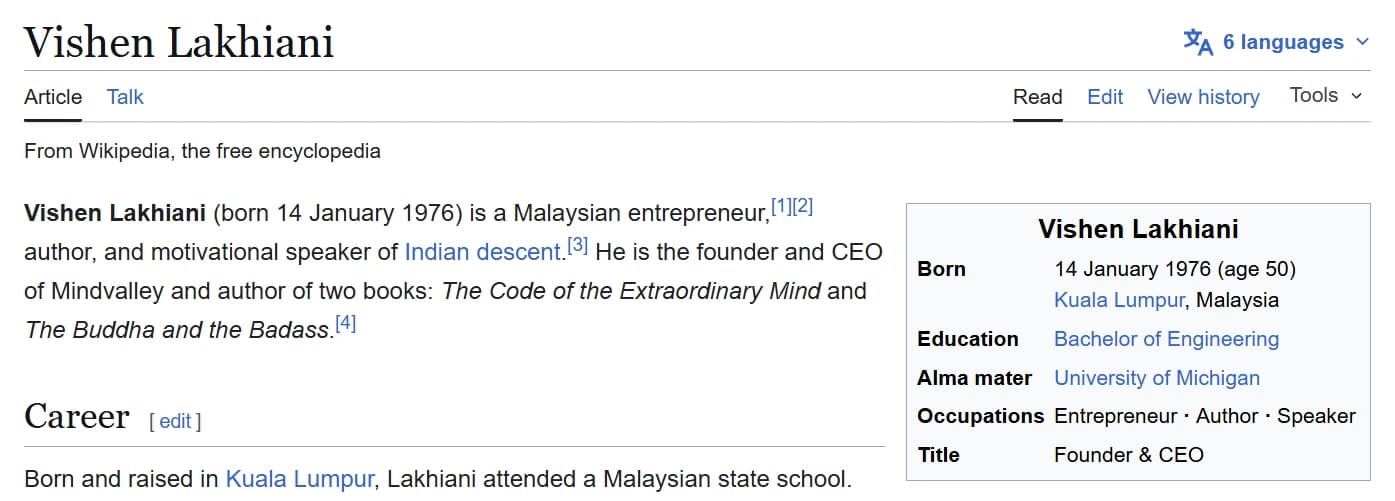
 Leggibile dalla macchina
Leggibile dalla macchinaGli screenshot sono esempi pubblici a scopo illustrativo. Le interfacce di ricerca e IA cambiano frequentemente; i risultati non sono garantiti.
Lavori selezionati
Pagine che abbiamo costruito — e difeso
15 anni. Oltre 4.000 aziende, fondatori e agenzie. Oltre 160 edizioni linguistiche di Wikipedia. Alcune voci che può verificare subito:
Scelti da fondatori & CEO, CMO e team di comunicazione, e agenzie PR/SEO (white-label).
- 15 anni
- Costruiamo e difendiamo la presenza Wikipedia dal 2010.
- 4.000+
- Aziende, fondatori e agenzie serviti.
- 93%
- Delle nostre pagine supera la revisione eliminazione di Wikipedia.
- 1.000+
- Pagine create e modificate ogni anno.
Il cambiamento
La ricerca non è morta. Si è spostata all'interno della risposta.
Per 20 anni il gioco consisteva nel posizionarsi sulla prima pagina di Google e guadagnare il clic. L'AI generativa ha cambiato la destinazione: le persone ora leggono la risposta e si fermano. Essere al #1 conta meno dell'essere la fonte da cui è costruita la risposta.
15% → 8%
Clic verso un sito qualsiasi quando appare una sintesi IA di Google
Pew Research, 2025
1%
Degli utenti clicca su un link all'interno della risposta IA stessa
Pew Research, 2025
~60%
Delle ricerche Google ora si conclude senza alcun clic
Bain & Company, 2025
Gartner prevede un calo del 25% del volume di ricerca tradizionale entro il 2026 man mano che le persone si spostano verso gli assistenti AI. Che la cifra esatta si realizzi o meno, la direzione è inequivocabile — e premia i brand che possiedono le fonti di cui l'AI si fida, non solo le parole chiave che Google classifica.
Come funziona
Come l'AI decide cosa dire di Lei
Una risposta AI sulla Sua azienda non viene estratta dal Suo sito web. Viene assemblata dalle fonti di cui il modello si fida. Ecco il percorso che il Suo brand deve fare per atterrare in quella risposta — accuratamente.
Il Suo marchio
- Azienda / fondatore
Fonti di cui l'IA si fida
- Wikipedia
- Wikidata
- Reddit · Quora
- Media di primo piano
Motori di risposta IA
- ChatGPT · Claude
- Gemini · Perplexity
- AI Overviews
Ciò che vede il Suo acquirente
- Una risposta
- accurata e citata
- su di Lei
Non nelle fonti? Il modello non ha nulla di affidabile da leggere — quindi parafrasa, usa fatti obsoleti, allucina o nomina un concorrente al Suo posto.
Tre livelli, una verità
L'AI la legge in tre posti — Wikipedia è in tutti e tre
Il livello di addestramento
Ogni modello con una ricetta di addestramento pubblicata campiona in eccesso Wikipedia. GPT-3 le ha attribuito il 3% del mix ma l'ha mostrata 3,4× — più di qualsiasi altra fonte — mentre mostrava l'intero web aperto meno di una volta. Meta's LLaMA: 4,5%. I modelli frontier mantengono segrete le loro ricette, ma il pattern è coerente.
Il livello di recupero
Quando ChatGPT, Perplexity, Gemini o Google AI Overviews cercano qualcosa in tempo reale, si rivolgono prima allo stesso set di alta fiducia: Wikipedia, Wikidata, Reddit, Quora e media di primo livello. Questi sono i domini più citati dall'AI.
Il livello delle entità
Dietro ogni risposta sicura c'è un'entità — di solito un Q-ID Wikidata. Con uno, l'AI la tratta come un'azienda nota con fatti verificati. Senza uno, è una stringa di lettere su cui deve indovinare.
Cosa è in gioco
Adesso l'AI risponde a domande su di Lei. Le sta rispondendo correttamente?
La differenza tra una risposta sicura e citata e un'alzata di spalle — o peggio, il nome di un concorrente — dipende dal fatto che l'AI abbia fonti affidabili da leggere su di Lei.
«Non ho informazioni affidabili su Acme Robotics. Potrebbe essere un'azienda più piccola — Le conviene controllare direttamente il loro sito ufficiale.»
«Acme Robotics è un'azienda di robotica per magazzini autonomi fondata nel 2018, con sede ad Austin, in Texas. Ha chiuso un round di Serie B nel 2024 ed è guidata dal CEO Jordan Lee.»
Come appare
Cosa restituisce l’IA quando la tua entità è documentata
Chiedi a un assistente IA di un’azienda con una presenza pulita su Wikipedia + Wikidata e otterrai una risposta sicura, strutturata e citata. Il livello sorgente decide se la risposta è accurata — o inventata.
Cos’è Northwind Robotics? Fornisci un breve riepilogo fattuale con fonti.
Northwind Robotics è un’azienda di automazione dei magazzini fondata nel 2017, con sede a Tallinn, in Estonia. Produce robot mobili autonomi per la logistica ed è stata nominata «azienda da tenere d’occhio» nel settore nel 2024. La fondatrice e CEO è Liis Saar.
Fonti
I fatti coincidono
Anno di fondazione, sede, leadership e categoria rimandano tutti a un articolo Wikipedia e a un’entità Wikidata — fonti di cui il modello si fida.
Senza di esse, l’IA indovina
Nessun record affidabile e la stessa domanda restituisce un’alzata di spalle, un dato obsoleto o il nome di un concorrente — senza nulla per correggerlo.
Esempio illustrativo per mostrare il comportamento tipico dell’IA con un’entità documentata — l’azienda mostrata è fittizia; non è uno screenshot live né un risultato garantito.
Le prove
Wikipedia è la fonte di cui l'AI si fida di più — per design
Questa non è un'affermazione di marketing. Emerge nelle ricette di addestramento dei modelli stessi e in ogni grande studio su cosa cita l'AI.
Dati di addestramento
Wikipedia è la fonte più campionata in eccesso in GPT-3
Citazioni live
Domini più citati in ChatGPT (illustrativo)
Copertura
Ogni motore legge un mix diverso. Li copriamo tutti.
Nessuna fonte singola vince ogni motore AI — Wikipedia guida ChatGPT, Reddit guida Perplexity e AI Overviews, Wikidata alimenta il Knowledge Graph. Una presenza coordinata è ciò che la rende visibile ovunque i Suoi acquirenti facciano domande.
| Fonte letta dall'IA | ChatGPT | Perplexity | Gemini | AI Overviews | WikiBusines |
|---|---|---|---|---|---|
| Wikipedia | |||||
| Quora | |||||
| Wikidata / Knowledge Graph | |||||
| Media di primo piano |
Wikidata · Knowledge Graph
Wikidata è la versione leggibile dalla macchina di Lei
Wikipedia è la storia; Wikidata sono i fatti strutturati. Insieme a Wikimedia Commons alimentano il Knowledge Graph di Google — il motore dietro il Knowledge Panel, gli assistenti vocali e i fatti che gli LLM restituiscono su di Lei.
La pipeline
Google Knowledge Graph
Oltre 8 mld di fatti su persone, luoghi e aziende
Un'entità Wikidata pulita — con gli identificatori, le date e le relazioni corretti — alza il livello minimo di come l'AI la descrive. Spesso muove l'ago più dell'articolo Wikipedia stesso. Scopra come funziona il lavoro Wikidata →
Cosa costruisce su Google
Acme Robotics
Azienda tecnologica
Acme Robotics è un'azienda di robotica che progetta sistemi di magazzino autonomi. È stata fondata nel 2018 e ha sede ad Austin, in Texas. da Wikipedia
- Fondata
- 2018 · Austin, TX Wikidata
- CEO
- Jordan Lee Wikidata
- Settore
- Robotica industriale
Non garantiamo un Knowledge Panel — i sistemi di Google prendono quella decisione. Il nostro compito è costruire la base verificata dell'entità che aumenta materialmente la probabilità, poi monitorarla.
Reddit · Quora
Dove l'AI va a cercare l'opinione 'reale'
Le enciclopedie danno all'AI i fatti; le community le danno il verdetto. Reddit e Quora sono ora tra le fonti più citate nelle risposte AI — e Google sta pagando per il privilegio.
~$60M/anno
Valore riportato dell'accordo di Google per licenziare i contenuti Reddit per l'addestramento e la ricerca.
CBS News / Reuters, 2024
85° → 7°
L'ascesa di Reddit tra i domini più visibili nella ricerca Google in meno di un anno.
Sistrix via Amsive, 2024
#1
Dominio più citato in Google AI Overviews e Perplexity: Reddit.
Profound, 680M citazioni, 2025
Quando le persone vogliono un parere onesto, aggiungono “reddit” alla ricerca. L'AI fa lo stesso. Una presenza conforme e non promozionale nelle community giuste è ora parte di come un brand rimane accuratamente rappresentato nelle risposte AI. Esplori la visibilità AI Reddit →
Autorità e portata
Il dominio più autorevole sul web aperto
Wikipedia registra una media di 508 milioni di visualizzazioni al giorno tra 66 milioni di articoli e 342 lingue. La sua autorità è il motivo per cui sia Google che l'AI si appoggiano ad essa — e perché una pagina in ogni mercato compone la sua credibilità a livello globale.
Autorità di dominio per edizione Wikipedia
| Lingua | Dominio | Domain Rating | Traffico stim. |
|---|---|---|---|
| English | en.wikipedia.org | 96 | ~4.4B / mo |
| German | de.wikipedia.org | 93 | ~320M / mo |
| French | fr.wikipedia.org | 93 | ~280M / mo |
| Spanish | es.wikipedia.org | 92 | ~500M / mo |
| Portuguese | pt.wikipedia.org | 91 | ~165M / mo |
| Chinese | zh.wikipedia.org | 90 | ~140M / mo |
| Arabic | ar.wikipedia.org | 90 | ~95M / mo |
| Ukrainian | uk.wikipedia.org | 85 | ~40M / mo |
- DR 96
- Domain Rating Ahrefs di en.wikipedia.org
- 508M
- Visualizzazioni medie Wikipedia al giorno
- 160+
- Edizioni linguistiche in cui pubblichiamo e manteniamo
Ahrefs, 2026
Pew Research, 2026
WikiBusines
La differenza
Con un livello sorgente affidabile — e senza
Stessa azienda, stesse domande. L'unica variabile è se esiste o meno un record su Wikipedia e Wikidata.
«Non ho informazioni affidabili su questa azienda.»
- Nessun Knowledge Panel su Google
- Risultati scarni — il proprio sito, poi directory casuali
- Le risposte IA sono vaghe, obsolete o ti ignorano a favore di un concorrente
«L'azienda X è una società [categoria] fondata nel [anno], con sede a [città], nota per …»
- Knowledge Panel con logo, fondatore e dati
- Snippet Wikipedia più media di primo livello nei risultati
- Le risposte IA sono sicure, accurate e citano le tue fonti
Modello illustrativo — basato sul comportamento comune di IA / ricerca, non un risultato garantito.
Il caso aziendale
Cosa fa per Lei una presenza Wikipedia costruita correttamente
Un asset, che lavora attraverso ricerca, risposte AI, stampa e sala consiglio.
Diventi la fonte citata dall'AI
Sia il riferimento verificato che ChatGPT, Claude, Gemini e Perplexity leggono — invece di essere parafrasato, datato o ignorato a favore di un concorrente.
Attivi il Google Knowledge Panel
Wikipedia + Wikidata sono i segnali più forti per la scheda laterale che inquadra il Suo brand nel momento in cui qualcuno cerca il Suo nome.
Sia padrone della prima pagina per il Suo nome
Wikipedia ha un Domain Rating Ahrefs di 96 e si posiziona per circa 45 milioni di parole chiave. Una pagina garantisce una visibilità duratura e ad alta intenzione — senza spesa pubblicitaria.
Superi la due diligence
Giornalisti, analisti, partner e investitori controllano prima Wikipedia. Una pagina neutrale e ben documentata è spesso il momento decisivo «questa azienda è reale» nello screening B2B e mediatico.
Raggiunga ogni mercato
Oltre 160 edizioni linguistiche significano credibilità localizzata immediata nelle regioni in cui opera — ognuna è una fonte affidabile e leggibile dall'AI.
Un asset che si compone
Costruito una volta e mantenuto, un'impronta Wikipedia/Wikidata continua a restituire fiducia e visibilità per anni — su superfici di ricerca che non esistevano quando ha iniziato.
L'ecosistema di visibilità IA
Otto piattaforme determinano ciò che l'IA dice del tuo brand
I motori di risposta IA leggono lo stesso insieme di fonti ad alta autorità di cui si fidano gli esseri umani. La copertura su ogni piattaforma si accumula — le lacune su una qualsiasi di esse sono evidenti.
Enciclopedia
Wikipedia
Oltre 160 edizioni linguistiche — il riferimento più citato del web aperto.
Perché: Fortemente ponderata da ogni grande LLM. La maggiore fonte di contesto di marca per le risposte IA.
Dati strutturati
Wikidata
Knowledge graph aperto — entità, relazioni e identificatori in forma leggibile dalle macchine.
Perché: Alimenta il Knowledge Graph di Google e viene letto direttamente dalle pipeline di recupero degli LLM.
Community
Discussioni a thread distribuite su migliaia di community.
Perché: I sistemi IA citano i thread di Reddit come «opinione reale degli utenti». Spesso mostrati nei risultati di Google.
Q&A / risposte IA
Quora
Piattaforma di domande e risposte con risposte approfondite di esperti.
Perché: Forte posizionamento organico e citazione diretta dai motori di risposta IA.
Dati strutturati
Google Knowledge Panel
La scheda laterale nei risultati di ricerca di Google.
Perché: Prima impressione per circa l'80 % delle ricerche di marca. Alimentata da Wikipedia + Wikidata.
Q&A / risposte IA
ChatGPT / Gemini / Perplexity
Motori di risposta a IA generativa.
Perché: Dove gli acquirenti si informano sempre più sui marchi prima di passare a Google.
Media
Media di livello 1 e 2
Media indipendenti che soddisfano il criterio di fonte attendibile di Wikipedia.
Perché: La spina dorsale della rilevanza. Senza di essi nessuna pagina Wikipedia è al sicuro dalla cancellazione.
Wiki alternativo
Simple English Wikipedia
Standard editoriali più semplici sulla stessa infrastruttura di Wikipedia.
Perché: Un percorso di pubblicazione più facile che eredita comunque l'autorità di dominio di Wikipedia.
Il problema
Perché non può semplicemente scriverla da solo
Wikipedia è una community indipendente con regole rigide, pubbliche e implacabili. È esattamente questo che rende una pagina preziosa — ed è esattamente il motivo per cui farlo da soli è rischioso.
200+ regole e policy
Notorietà, fonti affidabili, punto di vista neutrale, conflitto di interessi — Wikipedia è un'enciclopedia, non un canale di marketing. Il tono promozionale viene segnalato o eliminato.
La maggior parte delle pagine autoredatte viene rifiutata
Le stime del settore collocano il tasso di rifiuto per le pagine scritte dalle aziende intorno all'80-90% — fonti terze deboli, tono promozionale o mancanza di notorietà.
Non può scriverla da solo
Scrivere di se stessi è un conflitto di interessi. Se viene scoperto che il personale ha scritto la pagina, può essere contrassegnata o rimossa — e la fiducia con gli editor è difficile da ricostruire.
Un tentativo andato male può metterla in lista nera
I tentativi di eliminazione ripetuti lasciano un registro permanente e possono bloccare del tutto la creazione futura. Il percorso del freelancer economico da 50$ è come i brand finiscono per essere esclusi.
Il confronto onesto
Fai da te vs. freelancer vs. noi
| Internamente in proprio | Freelance su Upwork | Agenzia non specializzata | WikiBusines | |
|---|---|---|---|---|
| Notabilità valutata prima del pagamento | A volte | |||
| Scrittura enciclopedica e senza conflitto d'interessi | Rischioso | Rischioso | ||
| Entità Wikidata / Knowledge Graph | ||||
| Visibilità IA su Reddit e Quora | Raramente | |||
| Monitoraggio e difesa dopo la pubblicazione | A volte | |||
| Rimborso se una pagina eliminata non viene ripristinata | ||||
| Supera una revisione di cancellazione | ~10–15% | Bassa | Variabile | 93% di successo |
Una cornice onesta
Cosa promettiamo — e cosa non promettiamo
Il mercato dei servizi Wikipedia è pieno di garanzie che non possono essere mantenute. Questa è la linea che noi teniamo.
Lo faremo
Dirle quando la base di fonti supporta una pagina Wikipedia — e quando non è così.
Lo faremo
Costruire una presenza affidabile, neutrale e verificata nelle fonti su Wikipedia, Wikidata, Reddit e Quora.
Lo faremo
Rimborsare l'80% del compenso di progetto se una pagina eliminata non può essere ripristinata dopo 3 tentativi nei 90 giorni previsti.
Non lo faremo
Garantire la pubblicazione su Wikipedia. Wikipedia è una comunità indipendente con la propria revisione editoriale.
Non lo faremo
Promettere un Google Knowledge Panel. I sistemi di Google prendono quella decisione — noi aumentiamo significativamente la probabilità.
Non lo faremo
Affermare di poter inserire contenuti in ChatGPT o in qualsiasi altro modello. Costruiamo l'infrastruttura di fonti che i sistemi AI leggono.
Domande frequenti
Tutto quello che vuole sapere sui servizi Wikipedia
Idoneità a Wikipedia
Come stabilite se un'azienda è idonea a Wikipedia?
Quali soggetti non prendete in carico?
Cosa si intende per fonte affidabile?
I comunicati stampa contano come fonti?
La nostra copertura è prevalentemente su stampa di settore — funziona?
Processo e tempistiche
Quanto tempo richiede una pagina Wikipedia?
Cosa succede dopo la pubblicazione della pagina?
Come vengono effettuate le modifiche su pagine esistenti?
Non traducete — «localizzate». Cosa significa?
Garanzie e policy di rischio
Garantite che una pagina venga pubblicata?
Cosa succede se una pagina viene cancellata dopo la pubblicazione?
Potete garantire un Google Knowledge Panel?
Dichiarate di essere pagati per modificare Wikipedia?
Visibilità AI
Perché Wikipedia è importante per ChatGPT e la ricerca AI?
In che cosa la visibilità AI differisce dalla SEO?
Potete garantire che il mio brand appaia nelle risposte di ChatGPT?
Possiamo ottenere un Google Knowledge Panel senza una pagina Wikipedia?
Fonti e metodologia
Ogni numero su questa pagina è documentato
Costruiamo le pagine — inclusa questa — nel modo in cui l'AI premia: con statistiche verificabili, citazioni e fonti citate. Le quote di citazione variano per motore, studio e mese, quindi le presentiamo come intervalli e colleghiamo la ricerca.
- OpenAI / Brown et al. — Language Models are Few-Shot Learners (GPT-3), Table 2.2 (May 2020)
- Meta AI / Touvron et al. — LLaMA: Open and Efficient Foundation Language Models, Table 1 (Feb 2023)
- Ahrefs Brand Radar — Top 10 Most Cited Domains by AI Assistants (78.6M queries) (Jun 2025)
- Profound — AI Platform Citation Patterns (680M citations) (Jun 2025)
- Similarweb — Most-cited domains in ChatGPT answers (~600K citations) (Jan–Feb 2026)
- Pew Research Center — Google users are less likely to click when an AI summary appears (Jul 2025)
- Pew Research Center — Wikipedia at 25: what the data tells us (Jan 2026)
- Wikimedia Foundation — New user trends on Wikipedia (Oct 2025)
- Bain & Company — Consumer reliance on AI search results (Feb 2025)
- Aggarwal et al., Princeton / KDD 2024 — GEO: Generative Engine Optimization (GEO-bench, 10,000 queries) (Nov 2023)
- CBS News / Reuters — Google to pay Reddit ~$60M/year to train AI on its content (Feb 2024)
- Amsive — Reddit's explosive SEO growth (Sistrix / Ahrefs data) (May 2024)
- OpenAI (Sam Altman) via TechCrunch — ChatGPT has hit 800M weekly active users (Oct 2025)
- Alphabet Q2'25 (Sundar Pichai) via TechCrunch — Google's AI Overviews have 2B monthly users (Jul 2025)
- Gartner — Gartner predicts search engine volume will drop 25% by 2026 (Feb 2024)
- Ahrefs — Wikipedia Domain Rating & keyword footprint (Mar 2026)
Vuole vedere cosa dice l'AI di Lei adesso?
Eseguiremo un audit gratuito di visibilità AI — cosa dicono oggi ChatGPT, Claude, Gemini e Perplexity del Suo brand, dove sono le lacune nelle fonti e un piano realistico per risolverle. Nessun obbligo, nessuna presentazione commerciale.