Loading…
Why it matters · The AI era
800 million people ask ChatGPT every week, and 2 billion see Google's AI answers every month — and those models don't read your website. They read Wikipedia, Wikidata and Reddit. We build and defend the verified sources that decide what AI says about you.
15 years · 4,000+ Wikipedia & Wikidata projects · 93% survive Wikipedia's review · 160+ languages
The free audit shows what ChatGPT, Claude, Gemini & Perplexity say about you today — and a plan to fix the gaps. No obligation, no sales pitch.
Be the source every engine quotes
GPT-3 paper, OpenAI 2020
Ahrefs, 78.6M queries, 2025
Pew Research, 2025
CBS News / Reuters, 2024
Proof, not theory
Wikipedia is not just a page. It becomes the source layer behind search entity cards, AI summaries and due-diligence checks. Here is one public figure across three real, public surfaces — each reading from the same Wikipedia and Wikidata record.
 Source: Wikipedia
Source: Wikipedia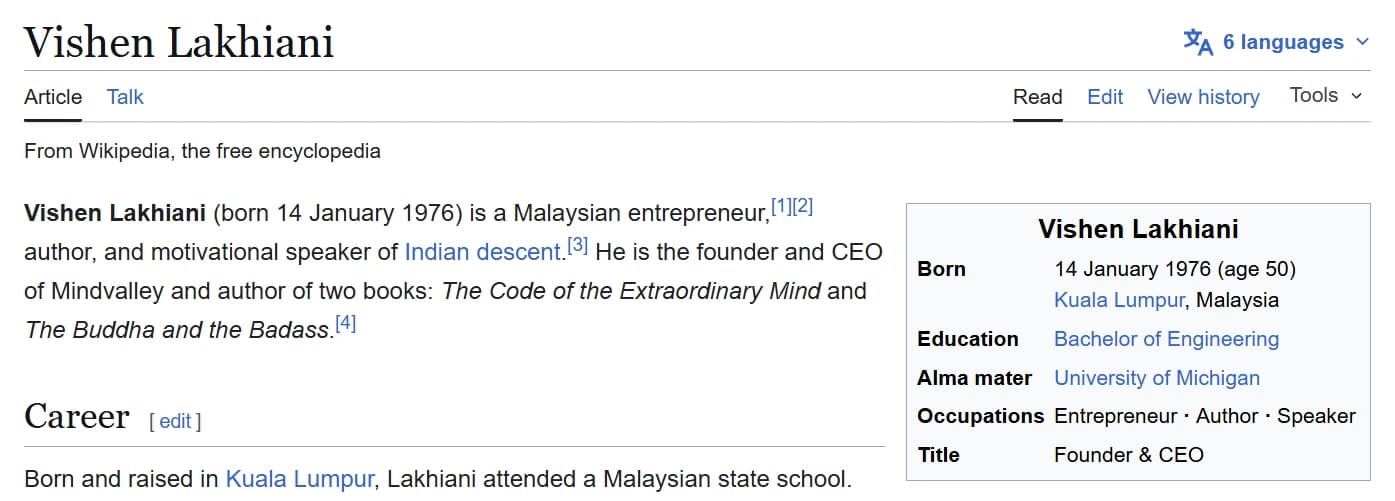
 Machine-readable
Machine-readableScreenshots are public examples captured for illustration. Search and AI interfaces change frequently; outcomes are not guaranteed.
Selected work
15 years. 4,000+ companies, founders and agencies. 160+ Wikipedia language editions. A few entries you can verify right now:
Trusted by founders & CEOs, CMOs and communications teams, and PR / SEO agencies (white-label).
The shift
For 20 years the game was ranking on Google's first page and earning the click. Generative AI changed the destination: people now read the answer and stop. Ranking #1 matters less than being the source the answer is built from.
15% → 8%
Clicks to any website when a Google AI summary appears
Pew Research, 2025
1%
Of users click a link inside the AI answer itself
Pew Research, 2025
~60%
Of Google searches now end with zero clicks
Bain & Company, 2025
Gartner predicts a 25% drop in traditional search volume by 2026 as people shift to AI assistants. Whether the exact figure holds or not, the direction is unmistakable — and it rewards brands that own the sources AI trusts, not just the keywords Google ranks.
How it works
An AI answer about your company isn't pulled from your website. It's assembled from the sources the model trusts. Here's the path your brand has to travel to land in that answer — accurately.
Your brand
Sources AI trusts
AI answer engines
What your buyer sees
Not in the sources? The model has nothing reliable to read — so it paraphrases, uses outdated facts, hallucinates, or names a competitor instead.
Three layers, one truth
The training layer
Every model with a published training recipe oversamples Wikipedia. GPT-3 weighted it 3% of the mix yet showed it 3.4× — more than any other source — while showing the entire open web less than once. Meta's LLaMA: 4.5%. Frontier models keep their recipes secret, but the pattern is consistent.
The retrieval layer
When ChatGPT, Perplexity, Gemini or Google AI Overviews look something up live, they reach for the same high-trust set first: Wikipedia, Wikidata, Reddit, Quora and tier-1 media. These are the domains AI cites most.
The entity layer
Behind every confident answer is an entity — usually a Wikidata Q-ID. With one, AI treats you as a known company with verified facts. Without one, you're a string of letters it has to guess about.
What's at stake
The difference between a confident, cited answer and a shrug — or worse, a competitor's name — comes down to whether AI has trusted sources to read about you.
“I don't have reliable information about Acme Robotics. It may be a smaller company — you might want to check their official website directly.”
“Acme Robotics is an autonomous-warehouse robotics company founded in 2018, headquartered in Austin, Texas. It raised a Series B in 2024 and is led by CEO Jordan Lee.”
How it shows up
Ask an AI assistant about a company with a clean Wikipedia + Wikidata footprint and you get a confident, structured, cited answer. The source layer decides whether the answer is accurate — or invented.
What is Northwind Robotics? Give a short factual summary with sources.
Northwind Robotics is a warehouse-automation company founded in 2017, headquartered in Tallinn, Estonia. It builds autonomous mobile robots for logistics and was named a 2024 industry “company to watch.” The founder and CEO is Liis Saar.
Sources
Founding year, headquarters, leadership and category all trace back to a Wikipedia article and a Wikidata entity — sources the model trusts.
No trusted record and the same question returns a shrug, a stale fact, or a competitor’s name — with nothing to correct it.
Illustrative example built to show typical AI behaviour with a documented entity — company shown is fictional; not a live screenshot and not a guaranteed result.
The evidence
This isn't a marketing claim. It shows up in the models' own training recipes and in every large study of what AI cites.
Training data
Live citations
Coverage
No single source wins every AI engine — Wikipedia leads ChatGPT, Reddit leads Perplexity and AI Overviews, Wikidata powers the Knowledge Graph. A coordinated presence is what makes you visible everywhere your buyers ask.
| Source AI reads | ChatGPT | Perplexity | Gemini | AI Overviews | WikiBusines |
|---|---|---|---|---|---|
| Wikipedia | |||||
| Quora | |||||
| Wikidata / Knowledge Graph | |||||
| Tier-1 media |
Wikidata · Knowledge Graph
Wikipedia is the story; Wikidata is the structured facts. Together with Wikimedia Commons they feed Google's Knowledge Graph — the engine behind the Knowledge Panel, voice assistants and the facts LLMs return about you.
The pipeline
Google Knowledge Graph
8B+ facts about people, places & companies
A clean Wikidata entity — with the right identifiers, dates and relationships — raises the floor on how accurately AI describes you. Often it moves the needle more than the Wikipedia article itself. See how Wikidata work runs →
What it builds on Google
Acme Robotics
Technology company
Acme Robotics is a robotics company that designs autonomous warehouse systems. It was founded in 2018 and is headquartered in Austin, Texas. from Wikipedia
We don't guarantee a Knowledge Panel — Google's systems make that call. Our job is to build the verified entity foundation that materially raises the probability, then track it.
Reddit · Quora
Encyclopedias give AI the facts; communities give it the verdict. Reddit and Quora are now among the most-cited sources in AI answers — and Google is paying for the privilege.
~$60M/yr
Reported value of Google's deal to license Reddit content for training and search.
CBS News / Reuters, 2024
85th → 7th
Reddit's climb among the most-visible domains in Google search in under a year.
Sistrix via Amsive, 2024
#1
Most-cited domain in Google AI Overviews and Perplexity: Reddit.
Profound, 680M citations, 2025
When people want an honest take, they add “reddit” to the search. AI does the same. Compliant, non-promotional presence in the right communities is now part of how a brand stays accurately represented in AI answers. Explore Reddit AI visibility →
Authority & reach
Wikipedia averages 508 million views a day across 66 million articles and 342 languages. Its authority is why both Google and AI lean on it — and why a page in each market compounds your credibility globally.
| Language | Domain | Domain Rating | Est. traffic |
|---|---|---|---|
| English | en.wikipedia.org | 96 | ~4.4B / mo |
| German | de.wikipedia.org | 93 | ~320M / mo |
| French | fr.wikipedia.org | 93 | ~280M / mo |
| Spanish | es.wikipedia.org | 92 | ~500M / mo |
| Portuguese | pt.wikipedia.org | 91 | ~165M / mo |
| Chinese | zh.wikipedia.org | 90 | ~140M / mo |
| Arabic | ar.wikipedia.org | 90 | ~95M / mo |
| Ukrainian | uk.wikipedia.org | 85 | ~40M / mo |
Ahrefs, 2026
Pew Research, 2026
WikiBusines
The difference
Same company, same questions. The only variable is whether a Wikipedia and Wikidata record exists.
“I don’t have reliable information about this company.”
“Company X is a [category] firm founded in [year], headquartered in [city], known for …”
Illustrative model — based on common AI / search behaviour, not a guaranteed result.
The business case
One asset, working across search, AI answers, the press and the boardroom.
Be the verified reference ChatGPT, Claude, Gemini and Perplexity read from — instead of being paraphrased, outdated, or skipped for a competitor.
Wikipedia + Wikidata are the strongest signals for the right-rail card that frames your brand the moment someone searches your name.
Wikipedia carries an Ahrefs Domain Rating of 96 and ranks for ~45M keywords. A page locks in durable, high-intent visibility — no ad spend required.
Journalists, analysts, partners and investors check Wikipedia first. A neutral, well-sourced page is often the deciding 'this company is real' moment in B2B and media screening.
160+ language editions mean instant, localized credibility in the regions you sell into — each one its own trusted, AI-readable source.
Built once and maintained, a Wikipedia/Wikidata footprint keeps returning trust and visibility for years — across search surfaces that didn't exist when you started.
The AI visibility ecosystem
AI answer engines read from the same set of high-authority sources humans trust. Coverage on each platform compounds — gaps on any one of them are noticeable.
Encyclopedia
160+ language editions, the most-cited reference on the open web.
Why: Heavily weighted by every major LLM. The single biggest source of brand context for AI answers.
Structured data
Open knowledge graph — entities, relationships and identifiers in machine-readable form.
Why: Feeds Google's Knowledge Graph and is read directly by LLM retrieval pipelines.
Community
Threaded discussions across thousands of communities.
Why: AI systems cite Reddit threads as 'real user opinion'. Often shown in Google Search results.
Q&A / AI answers
Q&A platform with expert long-form answers.
Why: Strong organic search ranking and direct citation by AI answer engines.
Structured data
The right-rail card on Google Search results.
Why: First impression for ~80% of branded searches. Powered by Wikipedia + Wikidata.
Q&A / AI answers
Generative AI answer engines.
Why: Where buyers increasingly research brands before clicking through to Google.
Media
Independent media that meets Wikipedia's reliable-source bar.
Why: The notability backbone. Without it, no Wikipedia page is safe from deletion.
Alt-wiki
Simpler editorial standards on the same Wikipedia infrastructure.
Why: Easier publication path that still inherits Wikipedia's domain authority.
The catch
Wikipedia is an independent community with strict, public, and unforgiving rules. That's exactly what makes a page valuable — and exactly why it's risky to DIY.
Notability, reliable sources, neutral point of view, conflict-of-interest — Wikipedia is an encyclopedia, not a marketing channel. Promotional tone gets flagged or deleted.
Industry estimates put the rejection rate for company-written pages around 80–90% — weak third-party sourcing, promotional tone, or a lack of notability.
Writing about yourself is a conflict of interest. If it's discovered that staff wrote the page, it can be tagged or removed — and trust with editors is hard to rebuild.
Repeated deleted attempts leave a permanent record and can block future creation entirely. The cheap $50 freelancer route is how brands get locked out.
The honest comparison
| DIY in-house | Upwork freelancer | Non-specialist agency | WikiBusines | |
|---|---|---|---|---|
| Notability assessed before you pay | Sometimes | |||
| Encyclopedic, COI-safe writing | Risky | Risky | ||
| Wikidata / Knowledge Graph entity | ||||
| Reddit & Quora AI-visibility | Rarely | |||
| Post-publication monitoring & defense | Sometimes | |||
| Refund if a deleted page isn't restored | ||||
| Survives a deletion review | ~10–15% | Low | Mixed | 93% success |
An honest frame
The Wikipedia services market is full of guarantees that can't be kept. Here's the line we hold.
We will
Tell you when the source base supports a Wikipedia page — and when it doesn't.
We will
Build a reliable, neutral, source-verified presence on Wikipedia, Wikidata, Reddit and Quora.
We will
Refund 80% of the project fee if a deleted page cannot be restored after 3 attempts in the 90-day window.
We won't
Guarantee Wikipedia publication. Wikipedia is an independent community with its own editorial review.
We won't
Promise a Google Knowledge Panel. Google's systems make that call — we materially raise the probability.
We won't
Claim to inject content into ChatGPT or any other model. We build the source infrastructure AI systems read.
Frequently asked questions
Sources & methodology
We build pages — including this one — the way AI rewards: with verifiable statistics, quotations and cited sources. Citation shares vary by engine, study and month, so we present them as ranges and link the research.
We'll run a free AI-visibility audit — what ChatGPT, Claude, Gemini and Perplexity say about your brand today, where the source gaps are, and a realistic plan to fix them. No obligation, no sales pitch.